N-grams
What are n-grams?
N-grams are strings of words which occur all in a row and are repeated within a text (or collection of texts). tPMHighlighter searches for repeated strings of 2, 3, 4, and 5 words in length.
A lexical bundle is a special kind of n-gram, where the frequency per million words and the number of texts in which they occur reach specified thresholds. With the default values of 10 times per million words and a minimum of 2 texts, lexical bundles will be high frequency n-grams in the readymade reference corpus and will occur in at least 2 different texts in the readymade reference corpus.
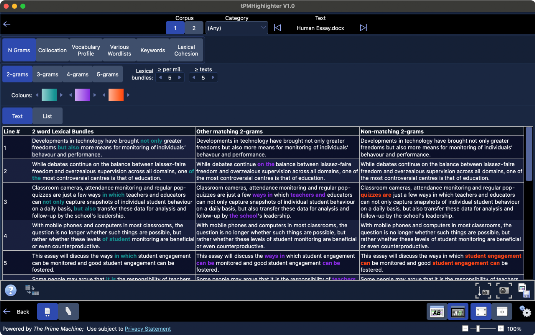
In the screenshot, we can see three columns of data. The green highlighting shows two word n-grams which occur more than five times per million words in the reference corpus and also occur in five or more texts in the reference corpus. These are called lexical bundles and are frequent building blocks of text for the chosen genre (in this case academic writing as found in the BNC: Academic corpus).
The second column shows other two word combinations in purple which are attested in the reference corpus (occurring at least once, but either not occurring as often as 5 times per million words or not occurring in at least five texts).
The third column shows repeated strings of two words from the text which are not found in the ready-made reference corpus. In this case, since we know that “student engagement” is a combination we see elsewhere, we can note that “student engagement” is an expression which is newer than the BNC: Academic corpus.
You can view a list of n-grams matching each sentence in your text by switching between Text and List just above the table of results.
You can select n-grams of different lengths using the buttons.
How does tPMHighlighter work with n-grams under the hood?
First, the software runs through each sentence in each text word by word and generates strings of words of between 2 and 5 words in length. Lists for each text are kept separate. If a string occurs more than once, it is shortlisted for checking against the readymade reference corpus. The reference corpus is checked to determine how often the string occurs in the reference corpus and in how many texts it occurs. If a match is found, the classification of “lexical bundle” is based on the settings shown on the results screen for the minimum frequency per million words and the minimum number of texts.
When a text is displayed, the n-grams for the individual text are used and different colours are used for different categories (lexical bundles, other matching n-grams and non-matching n-grams) and different shades of colour indicate the frequency of the n-gram within the currently viewed text.
Note that as in the screenshot, language use does change across different genres, different domains and over time. Therefore, try to choose the most appropriate readymade corpus for your needs when you build your corpus.