Lexical Cohesion
What is lexical cohesion?
Sentences in a text tend to be connected to other sentences through the repetition of words and through common themes. The lexical cohesion results in tPMHighlighter aim to provide insights into the likely lexical cohesion within and across texts through two processes: the matching of simple repetition of word families (Hoey, 1991) and the matching of words according to the top three semantic groups, drawing on UCREL’s Semantic Analysis (Rayson et al. 2004) labels which are key in the readymade online corpus.
The “family relations” measure shows words which contribute to the links between bonded sentences (see Hoey, 1991 for an explanation of links and bonds).
The Top 3 themes show words which match words in the readymade corpus which have been marked in the readymade corpus as having a tendency to be related to a semantic label. Themes will not always be accurate, but they should give a summary of general topic areas or the general focus.
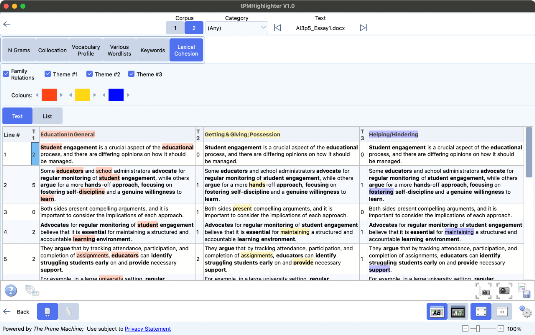
In the screenshot we can see that three themes have been identified. Although not all the words highlighted will match the theme exactly, we can see that overall there are several words related to each theme. The simple repetition of word families is shown in bold, where items in bold contribute a link to bonds between sentences.
Lexical Cohesion on the Explore Corpora screen
When you use the Explore Corpora results screen for Lexical Cohesion, you can also perform cross-text or cross-corpus analysis.
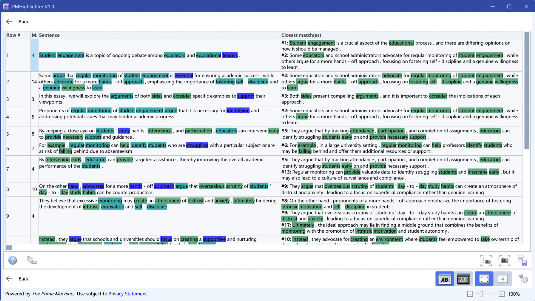
You will see a grid of texts from either one corpus or both corpora, with percentages showing the proportion of sentences which are bonded between the two texts corresponding to the grid coordinates. If you click the percentage, another screen will appear showing the first text on the left and the closest matching sentences from the other text on the right. Words contributing to the bond score between the closest matching sentences and the original sentences will be shown in green (or the first colour). The other words that are highlighted are words which are also making links between other sentences in the text pair, or words that make links with other sentences in other texts.
How does tPMHighlighter work with semantic labels and word family links under the hood?
When the corpus is built, the wordlist for your corpus is sent to The Prime Machine server. tPMHighlighter uses Nation’s (2017) BNC+COCA wordlist for a general all-purpose list of English words, grouped into word families, and – if an item cannot be found there – the word family from the wordlist from the readymade corpus selected when the corpus is built. At the same time, words (types) that match items in the readymade corpus are checked to see which of the USAS labels (Rayson, 2004) have been stored for this item in the readymade corpus. For information about how USAS labels are determined to be important for a word in the readymade corpus, see Jeaco (2020b).
When a text is displayed, each word that contributes to a bond between sentences will be shown in bold. The semantic labels are checked for all words in the text and the top three labels are determined based on frequency. Words which have been marked in your corpus because the words have this semantic label in the readymade corpus can be highlighted in colour.
Note: tPMHighlighter does not tag your texts for part-of-speech and it does not tag them using UCREL’s Semantic Analysis System directly; the USAS labels shown in the Lexical Cohesion tool are based on the tendencies for matching words (types) found in the readymade corpus. It is therefore an indirect type-based match to items in the reference corpus. See ucrel.lancs.ac.uk/usas/, Wmatrix or LancsBox for tools to actually tag your texts.